

Some, but still very little, study has been done in the way of examining the differences
between singing and speech. What can be distinguished very clearly by the ear becomes more
problematic when examined by spectrogram. When examining trained classical singers, a few
clear differences arise, such as the presence of the so-called “singer’s formant” and vibrato.
However, when discussing technique with trained operatic singers, the way they form their
words—particularly vowels—with their vocal tracts differs radically from everyday speech. This
raises the question: when operatic singers apply similar techniques to speech to modify their
speaking voices—hereby known as “operatic speech”—are their mannerisms more speech-like
or song-like? By recording three operatically trained tenors in several seconds of singing, speech,
and operatic speech, I examined the differences and similarities between all three forms,
specifically focusing on formants in the vowels. I hypothesized that when trained singers spoke
operatically, singer’s formant would be present and the formants on their vowels would more
closely mirror singing than normal speech.
Research has led to the discovery of a phenomenon called “singer’s formant.” Present
only in male singing voices, singer’s formant is a resonance that occurs around 3000 Hz. When
an opera singer performs, they are often singing accompanied by a full orchestra. A single man’s
voice cannot compete with dozens of instruments, so they must change the way they produce
sound in order to be heard over the orchestra without straining their vocal folds. The weakest
part of the orchestral spectrum is about 3000 Hz, so a singer can change the formation of his
vocal tract to cluster the third, fourth, and fifth formants to produce the resonance in the
orchestra’s weak spot and be better heard. In order to make this change, a singer can lower his
larynx, widen his pharynx, laryngeal ventricle, and his piriform sinuses located above the vocal
folds. (Kreiman 2011)
Singer’s formant occurs in all male voice parts, but at varying frequencies. For example,
most professional basses have a singer’s formant that falls in a range of about 2300 Hz – 2500
Hz, most baritones’ are between 2500 Hz and 2700 Hz, and tenors tend to fall between 2700 Hz
– 2900 Hz. The differences between singer’s formant in voice part can likely be attributed to
vocal tract length. Basses tend to have the longest vocal tracts, between 23.5 and 25 cm,
baritones tend to have vocal tracts between 21.5 and 24 cm, and tenors often fall between 19 cm
and 22 cm (Dmitriev 1979). The longer the tract, the lower the voice, and therefore, the lowering
of the larynx has different effects on the frequency of the singer’s formant. As for women, altos
have a much weaker singer’s formant than men, and sopranos have no singer’s formant at all.
Interestingly enough, famous sopranos have more energy in these high frequencies than less
famous sopranos, implying that a high-pitched female voice that carries these frequencies may be
the key to success. In addition to all the voice parts, it was found that untrained non-singers also
do not have a singer’s formant, meaning that this frequency is found through training (Sundberg
1990).
This mysterious frequency has been the subject of much question and study. As scientists
and linguists dig into the subject, some questions have been answered and others remain. For
example, one study took ten acclaimed tenors trained in either a Western or Chinese style, had
them sing the vowels /ɑ/, /i/, and /u/, and had 19 voice teachers rate each vowel on a one to seven
scale of brightness. A narrow strip of colored tape was placed on each singer’s neck at a right
angle to the airway and the singer was filmed by the researchers. A computer analyzed the vocal
recordings for acoustic features. The results found that all subjects’ voices were reported to be in
the “bright range” with varying degrees. Across the board, /i/ and /ɑ/ were judged to be brighter
than /u/. For the Chinese-style tenors, the larynx generally was raised above its normal position
while singing, especially when they sang in their higher range, and the Western singers’ larynges
were usually below its normal resting position. This rule was even true for the singers who could
sing in both styles: when they sang Chinese, the larynx was raised, and when they sang Western,
the larynx was lowered. Furthermore, when the pitch increased in the Chinese singers, the larynx
moved up, and the opposite occurred in the Western singers. All of the formants’ frequencies
were higher in the Chinese style than in the Western style. The Western singers’ sung vowel
phonations were often lower than their spoken, and there were five or six formants present in the
Western vowels and only four or five in the Chinese style. In both cases, the upper formants
demonstrated clustering. (Wang 1986) This study was relevant to my experiment because it
explains some of the phenomena on the three western tenors’ spectrograms and measurements.
In most cases for most formants, their speech phonations were higher than their sung ones, and
any that deviated from this rule could be explained by a small sample size, natural variation, and
potentially any incorrect readings from the software (though I accounted for obvious machine
mistakes by finding the approximate frequency manually). This also notes five or six formants in
each vowel for each singer, which I also noted, though I only recorded the first four formants for
each vowel.
What else differentiates singing from speech? An important difference to note is
amplitude. When speaking casually, one only projects his voice to be heard by those around him,
but a singer must often sing loud enough to fill an entire auditorium or theatre and be heard over
a full orchestra. Singer’s formant and differently shaped vowels help produce amplitude, but
several other factors play into it as well. Higher sub-glottal pressure reflects louder amplitude,
though higher pitch also requires higher sub-glottal pressure. When speech was evaluated for
subglottal pressure as well, it was found that nonsense speech produced practically no sub-glottal
pressure, but emotional stresses on certain important syllables were created using this pressure as
well. Normally, loudness in speech is controlled by shifts in fundamental frequency, so
amplitude produced by sub-glottal pressure in speech is better characterized by “stress.” Pitch
passively rises with amplitude when speaking due to the shift in fundamental frequency, which
cannot happen if a singer wishes to sing different pitches at a loud amplitude. Therefore, it makes
sense that they would need to use sub-glottal pressure to increase amplitude. (Sundberg 1990)
Another notable difference between speech and operatic singing is the way that singers
form vowels. In everyday speech, the mouth’s goal is to find the most efficient way to form each
sound. However, singing often has extended vowels and efficiency is less important than
amplitude. For example, the most efficient way to say the “corner vowel,” or a vowel created in
an extreme corner of the mouth (front high, front low, back high, back low), /i/ is to lift the
tongue up to the front upper edge of the mouth. The resonant chamber in the oral cavity then is
located behind the tongue, so it carries less sound than another corner vowel, /ɑ/, which is
located at the very back and bottom of the mouth. When making the vowel /ɑ/, the resonant
chamber in the oral cavity is located primarily in front of the tongue and allows for more sound
to be heard. In order to make every vowel clear, operatic singers are taught to make vowels such
as /i/ in a different way. To make /i/, a singer will lift the middle-back of the tongue to the roof of
the mouth. This sounds the same as a front high /i/ to a listener, but is more amplified and can
better be heard over an orchestra in a large auditorium. (McCreary)
Due to the specific example of how to differently form vowels, I decided to test the
differences between vowels when sung operatically, spoken normally, and spoken with an
operatic tone to the voice. The two areas on which I focused were the presence of “singer’s
formant” in sung and operatically spoken text and also the differences in formant clustering
between the all three ways of delivering the lyrics.
To perform this experiment, I selected three tenors to record. The first, Connor
McCreary, is a 23-year old tenor who recently graduated the Thornton School of Music at the
University of Southern California’s undergraduate program in vocal performance. The second,
Anthony Moreno, is a 30-year old tenor currently enrolled in Thornton’s doctoral program, and
the third, Kyle Chase, a 25-year old tenor enrolled in the same doctoral program. Each of them
choose an English-language classical song in their repertoire so they would be familiar with the
lyrics and be able to sing it to the best of their abilities. Each subject then 1) sang the line of their
song, 2) spoke the same lyrics in a normal speaking voice, and 3) spoke the lyrics in an operatic
singing voice. They then recorded themselves speaking freely, describing what they were doing
with their vocal tracts when singing and speaking operatically. I then examined the spectrograms
of each subject, especially taking note of their vowels and formants.
First, I selected either the entire line they chose or part of the line and counted how many
vowels were present. Kyle’s lyric of choice, “When the air sings of summer I must wander
again” had 13 vowels present when counting diphthongs as one vowel. Connor’s lyric, “Come
under the shadow of this gray rock” had 10 vowels when considering diphthongs one vowel, and
Anthony’s lyric, “In the evening as far as the eye can see, herds of black pianos” had 17 under
the same condition. Closely examining each vowel, it became clear that all of Connor’s vowels
had a formant present at 3000Hz, all but one of Anthony’s did, and all but two of Kyle’s did as
well. When looking at the normally spoken versions of these three lyrics, Anthony and Kyle had
no formants that could be mistaken for a singer’s formant, and while Connor’s reading had many
formants at 3000Hz, his free speech showed several formants at 3000Hz on various vowels,
meaning his natural speaking voice happened to have some formants in this range. Finally, when
examining each operatically spoken version of the lyric, it became clear that for every vowel that
had a singer’s formant in the sung version, the same formant was present in the operatically
spoken version.
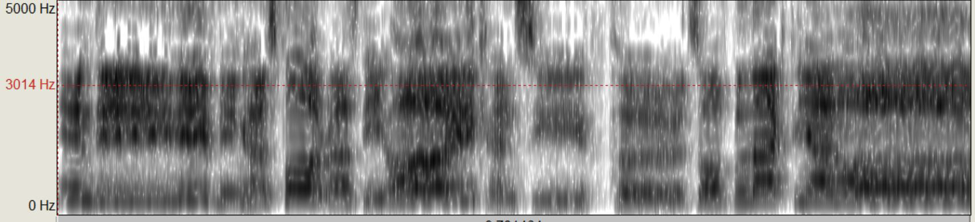
Figure 1: Anthony’s singer’s formant for the lyric “In the evening as far as the eye can see, herds of black pianos”
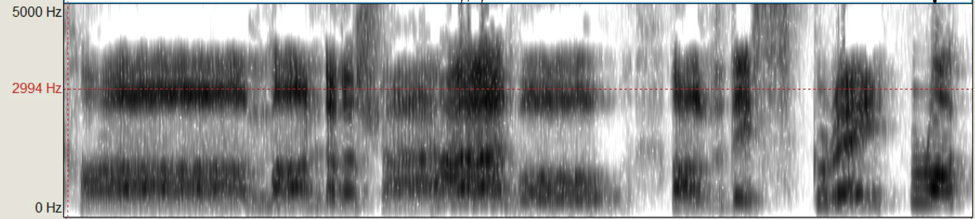
Figure 2: Connor’s singer’s formant for the lyric, “Come under the shadow of this gray rock”
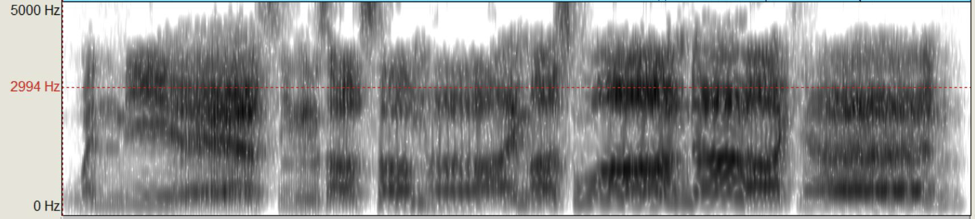
Figure 3: Kyle’s singer’s formant for the lyric “When the air sings of summer I must wander again”
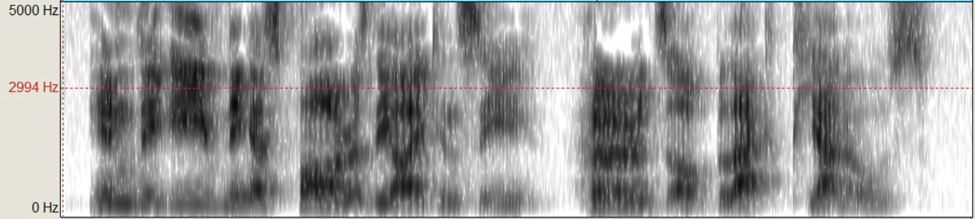
Figure 4: Anthony’s singer formant present when operatically speaking the lyric, “In the evening as far as the eye can see, herds
of black pianos”
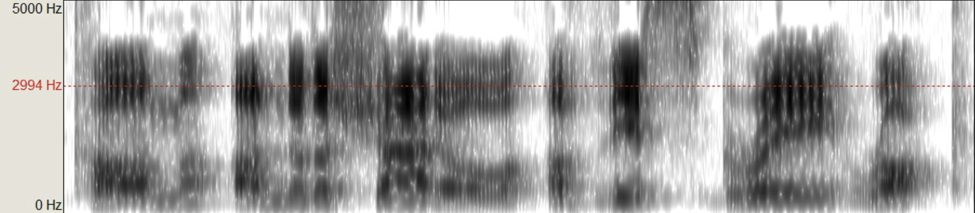
Figure 5: Connor’s singer’s formant present when operatically speaking the lyric, “Come under the shadow of this gray rock”
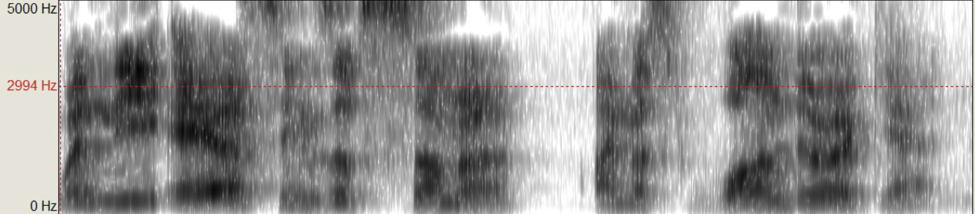
Figure 6: Kyle’s singer’s formant present when operatically speaking the lyric, “When the air sings of summer I must wander
again”
Another difference of interest between operatic speech and singing is generally the
placement and clustering of formants. To test this, I picked all the corner vowels present in the
three chosen lyrics: /i/, /æ/, and /ɑ/. In none of the three songs did the corner vowel /u/ appear.
After finding the first, second, third, and fourth formant for every clear instance of each vowel, I
averaged the data together to find a mean F1, F2, F3, and F4 for every vowel when sung, spoken,
and spoken operatically. Finding a mean helps to account for the variability that occurs naturally
between speakers and contexts of the vowel. I then compared each vowel across singing, speech,
and operatic speech, using the average spoken formants from a 1995 study (Hillenbrand 1995) as
a control.
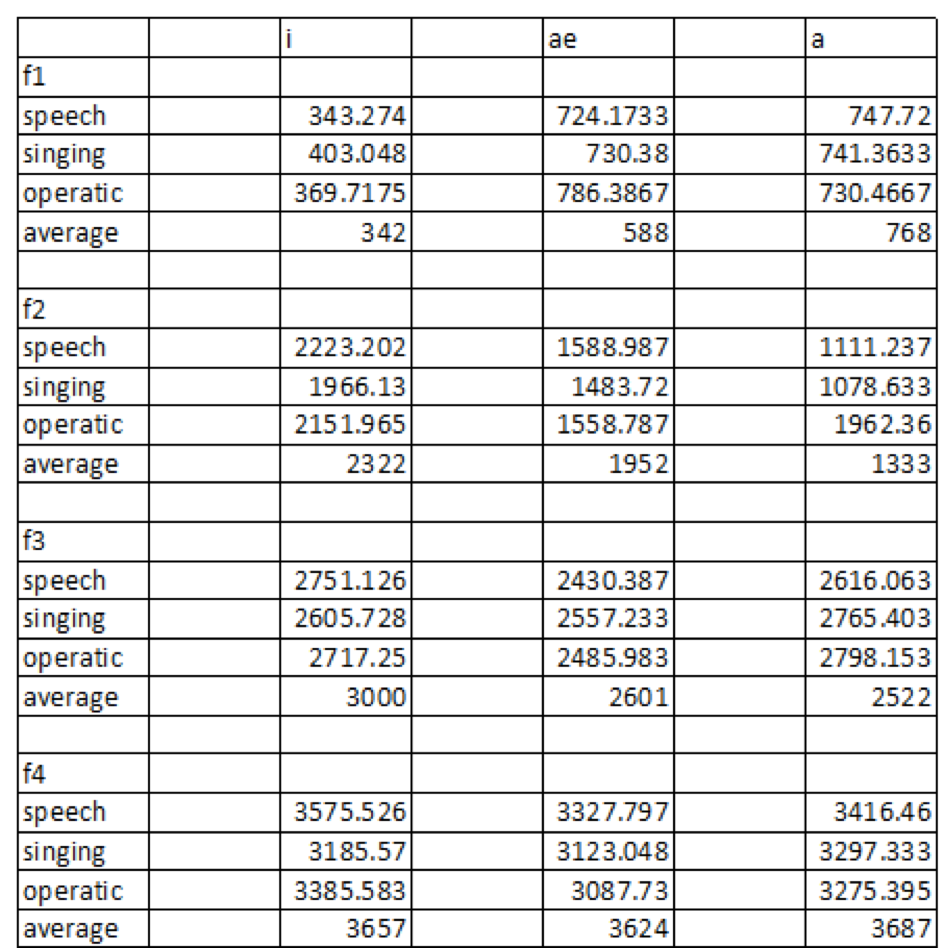
Figure 7: All recorded numbers are in Hz and “average” refers to Hillenbrand 1995
When the formants for each vowel were compared to one another across speech, singing,
and operatic speech, there was no pattern for formant similarity across all vowel types. However,
for all four formants for /i/, speech and operatic speech had closer frequencies. For /æ/, speech
and operatic speech had more similar frequencies for F2 and F3, and for /ɑ/, speech and singing
had closer F1 and F2s and singing and operatic speech had more similar frequencies for F3 and
F4. Therefore, it can be concluded that singing and operatic voice do not share more similar
formant frequencies than operatic voice and speech or speech and singing.
One important aspect of singer’s formant is the clustering of F3, F4, and F5. To examine
whether or not this clustering occurs during operatic speech, I subtracted F3 from F4 for all three
delivery types and compared the differences as follows:
Formant 4 Minus Formant 3
/i/ /æ/ /ɑ/
Speech 824.40 897.41 800.39
Singing 579.84 565.815 531.93
Operatic Speech 668.33 601.75 477.24
As can be seen here, there is a difference of about 800-900 Hz for all corner vowels when
these three men speak them. However, there is only a difference of 477-668 Hz when singing or
speaking them operatically. These differences provide evidence that F3 and F4 are clustered
closer together when singing or speaking operatically, which also helps to prove that the
resonance seen in the spectrograms for operatic speech is, in fact, singer’s formant.
The fact singer’s formant and formant clusters are present in operatic speech reveals
several facts about what operatic speech truly is. In order to speak operatically, the subject
lowered his larynx and widened his pharynx just as he would to sing over an orchestra. Another
revelation about what a singer must do to speak operatically relies on amplitude. As evidenced
by this waveform of Anthony’s singing, operatic speech, and normal speech, respectively,
singing has the highest amplitude, normal speech has the lowest, and operatic speech is
somewhere in the middle.
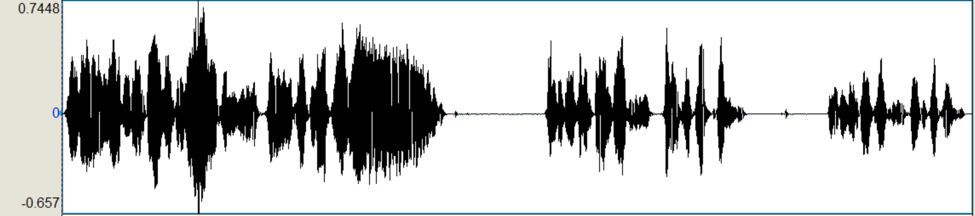
Figure 8: Anthony’s amplitude
Is this change in amplitude due to sub-glottal pressure or change in fundamental
frequency? Upon reviewing the spectral slice for the syllable /o/ of “pianos,” I found an
approximate F0 of 300 Hz for the sung syllable, an F0 of about 100 Hz for the operatically
spoken syllable, and about 90 Hz for the spoken syllable. As the fundamental frequencies are
quite similar between the two spoken syllables, it can be assumed that the reason for operatic
speech being louder than normal speech is due to the same sub-glottal pressures that, in addition
to higher fundamental frequencies, help produce high amplitudes in operatic singing. Therefore,
sub-glottal pressure can be added to the list of changes the subjects made to their vocal tracts to
produce operatic speech.
If all of these changes to the vocal tract can be made when speaking, what then
differentiates operatic speech from operatic singing? One difference is length of time. Many
songs require certain notes be sustained for a length of time, and generally, each syllable is given
more time in song than in speech. For example, when Connor sings the syllable /ʃæd/ of the word
“shadow,” the syllable is 1.44 seconds long. When he speaks the same syllable, it is only .35
seconds in length. When researchers sought to convert recorded speech into synthesized song,
duration of phonemes was one of the manipulated variables (Saitou 2007). The other acoustic
features they manipulated that represent the difference between speech and song are the
fundamental frequency and spectrum. The fundamental frequency represents pitch, which varies
in natural speech but varies even more in music as each pitch represents a musical note. They
also identified four other factors present in the fundamental frequency that differentiated between
speech and song: “1. Overshoot: a deflection exceeding the target note after a note change. 2.
Vibrato: a quasi-periodic frequency modulation (4-7 Hz). 3. Preparation: a deflection in the
direction opposite to a note change observed just before the note change. 4. Fine fluctuation: an
irregular frequency fluctuation higher than 10 Hz” (Saitou 2007). Vibrato can clearly be seen in
the singing of each tenor, as represented by the sine-wave like design in the following
spectrogram of Connor’s vowel /æ/ in the syllable /ʃæd/:

Figure 9: Evidence of vibrato in the syllable /ʃæd/
The same sine-wave like pattern is not present in either the normally spoken lyric or the
operatically spoken lyric, meaning that vibrato is a feature unique to singing alone and
differentiates it from operatic speech.
Operatic speech, while not a commonly known or used phenomenon, is an interesting
middle ground between singing and speech. Although speaking operatically does not appear to
change the fundamental frequency of someone’s voice, the singer’s formant and formant
clustering could confuse a linguist trying to match spectrograms of someone’s voice and could
serve as a convincing vocal disguise. The one downfall to this form of disguise is that the only
community that could use it would be operatically trained males, which, unless someone were
trying to solve a bomb threat at an opera house, would likely end up pointing to a suspect. All
this form of speaking requires is a lowered larynx, widened pharynx, and similar sub-glottal
pressure to emotionally stressing a syllable. Someone could potentially learn how to mimic this
technique, though it would take explicit instruction as untrained singers did not exhibit the same
formant clusters and singers’ formants. Overall, this way of manipulating one’s voice proves to
share many similarities with singing, with only vibrato, duration, some amplitude, and some
variations related to fundamental frequency keeping it as speech instead of song. Operatic speech
serves as a sort of bridge between singing and speech, sharing attributes with both and
connecting them together.
Laura Russell is a current junior at the University of Southern California pursuing a double-major in Linguistics and Communication. Outside of the classroom, she works as a tutor in the Student-Athlete Academic Services department and participates on the board of Undergraduate Students in Linguistics. After graduation, she plans to attend law school in order to pursue a career in trademark law.

Bibliography
Dmitriev, L., & Kiselev, A. (1979). Relationship between the Formant Structure of Different
Types of Singing Voices and the Dimensions of Supraglottic Cavities. Folia Phoniatrica
Et Logopaedica, 31(4), 238-241. doi:10.1159/000264170
Hillenbrand, J., Getty, L. A., Clark, M. J., & Wheeler, K. (1995, January 17). Acoustic
characteristics of American English vowels. The Journal of the Acoustical Society of
America, 97(5), 3099-3111. doi:10.1121/1.411872
Kreiman, J., & Sidtis, D. (2011). Foundations of voice studies: An interdisciplinary approach to
voice production and perception. Chichester, West Sussex: Wiley-Blackwell.
McCreary, C. (n.d.). Physical Characteristics of Operatically Sung Vowels [Personal interview].
Saitou, T., Goto, M., Unoki, M., & Akagi, M. (2007, October 21-24). Speech-to-Singing
Synthesis: Converting Speaking Voices to Singing Voices by Controlling Acoustic
Features Unique to Singing Voices. 2007 IEEE Workshop on Applications of Signal
Processing to Audio and Acoustics, 215-218. doi:10.1109/aspaa.2007.4393001
Sundberg, J. (1990). What’s so special about singers? Journal of Voice, 4(2), 107-119.
doi:10.1016/s0892-1997(05)80135-3
Wang, S. (1986). Singer’s high formant associated with different larynx position in styles of
singing. Journal of the Acoustical Society of Japan, 7(6), 303-314. doi:10.1250/ast.7.303
Leave a Reply